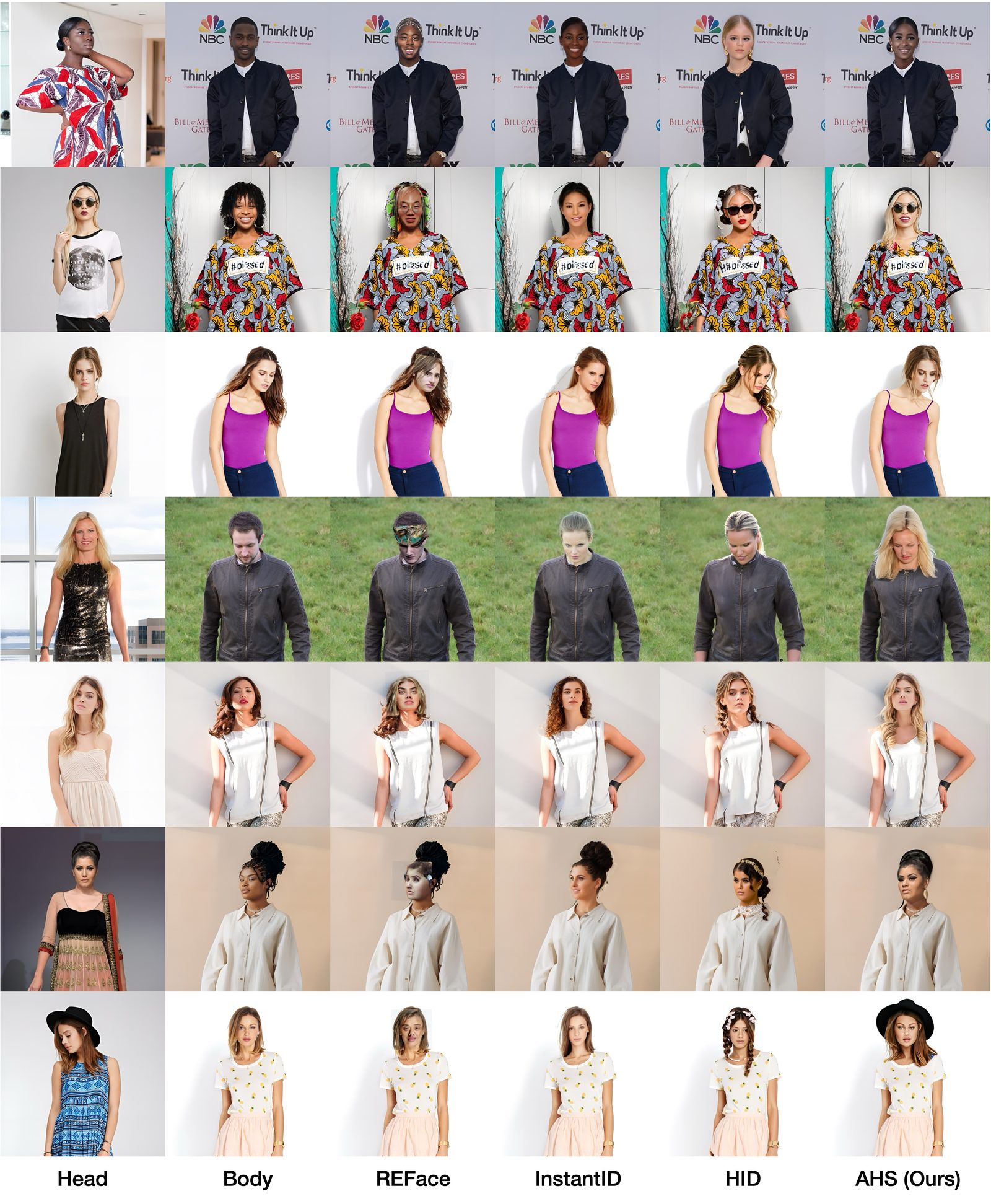
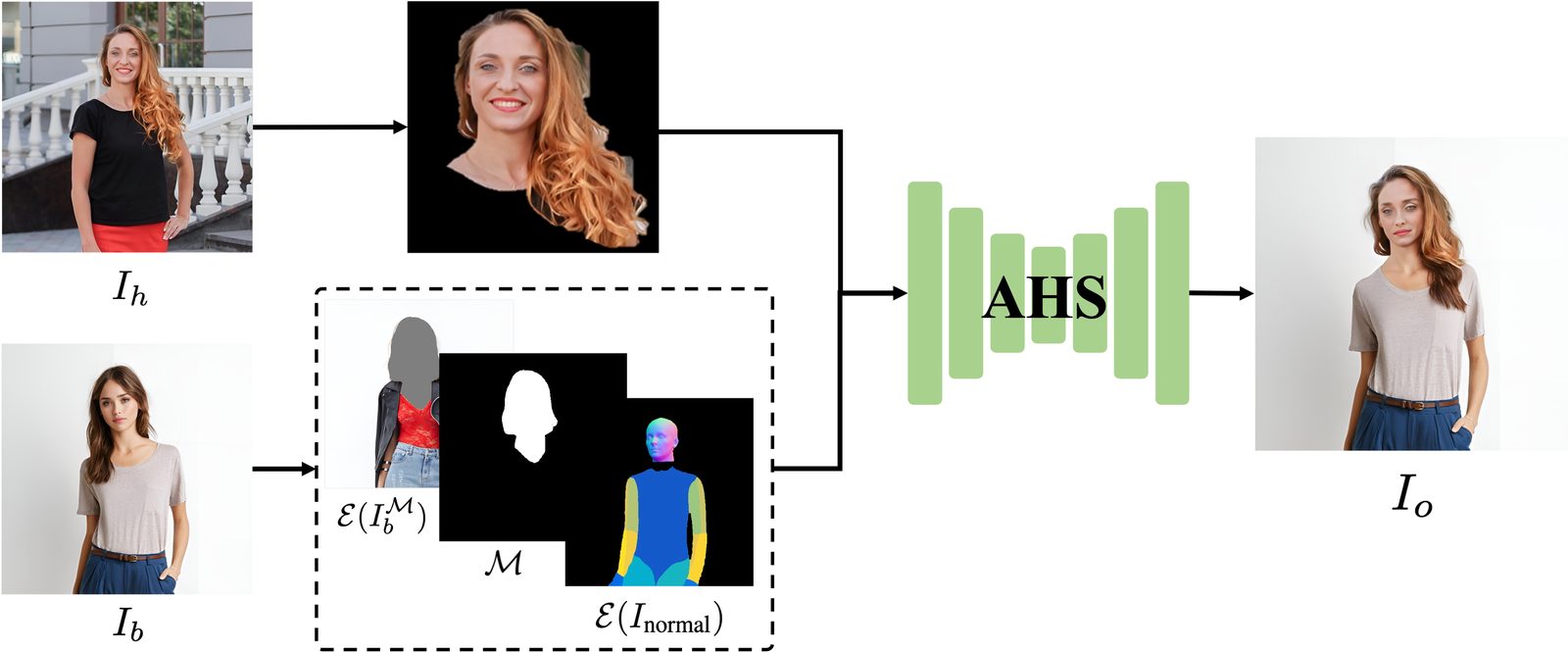
| Method | CLIP-I (Head) ↑ | FID ↓ | FID (Crop) ↓ | ID sim ↑ | Head Orient. ↓ | Expression ↓ |
|---|---|---|---|---|---|---|
| REFace | 0.7859 | 8.4491 | 24.31 | 0.5239 | 5.57 | 7.308 |
| InstantID* | 0.8223 | 5.7882 | 11.43 | 0.2829 | 7.52 | 7.591 |
| HID | 0.8577 | 5.6306 | 6.83 | 0.5555 | 11.51 | 8.474 |
| AHS (Ours) | 0.9132 | 5.7818 | 5.02 | 0.6230 | 8.01 | 6.204 |
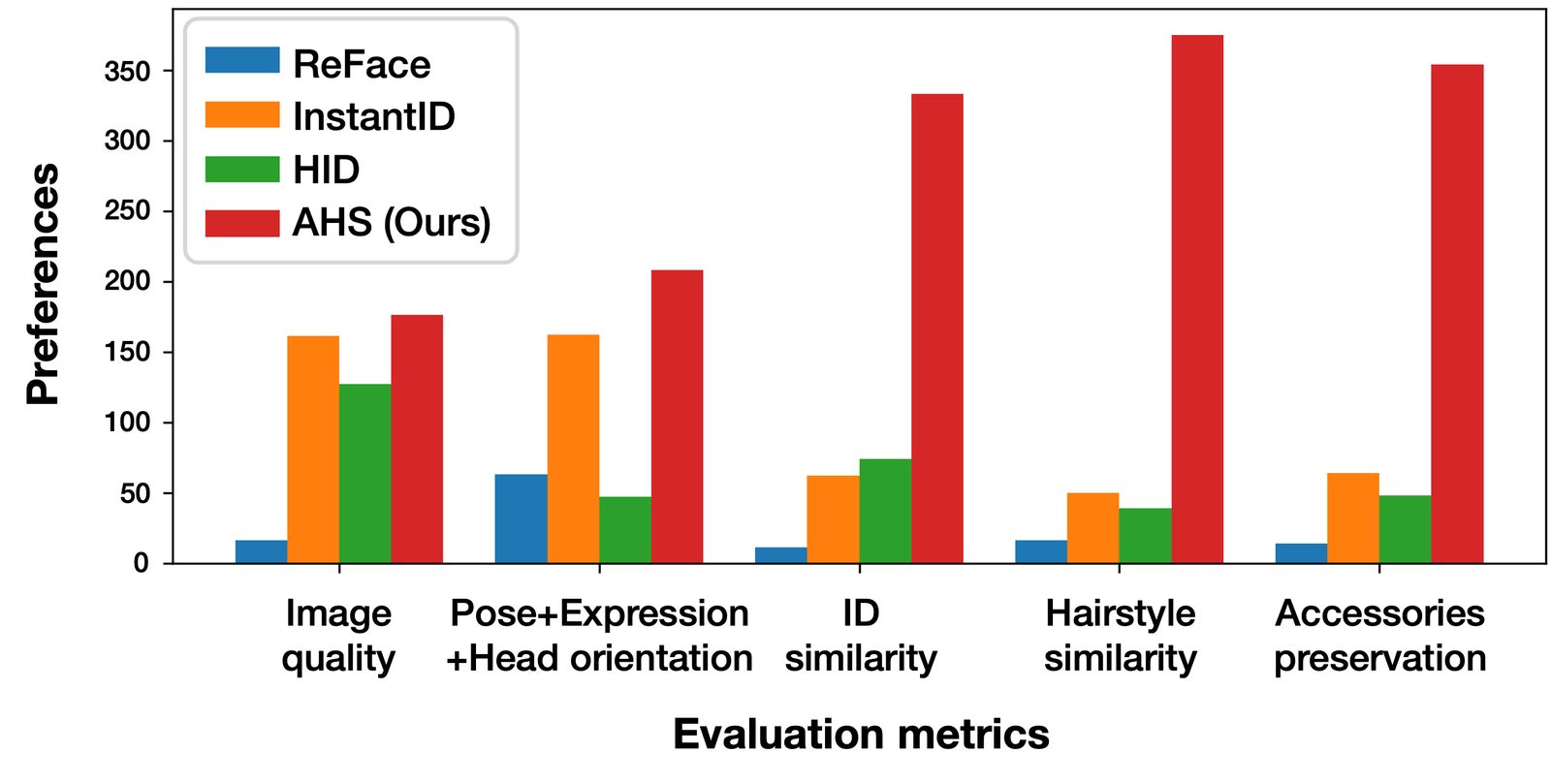
Quantitative comparison. Best and second-best results are in bold and underlined, respectively. AHS outperforms existing methods in most metrics.