



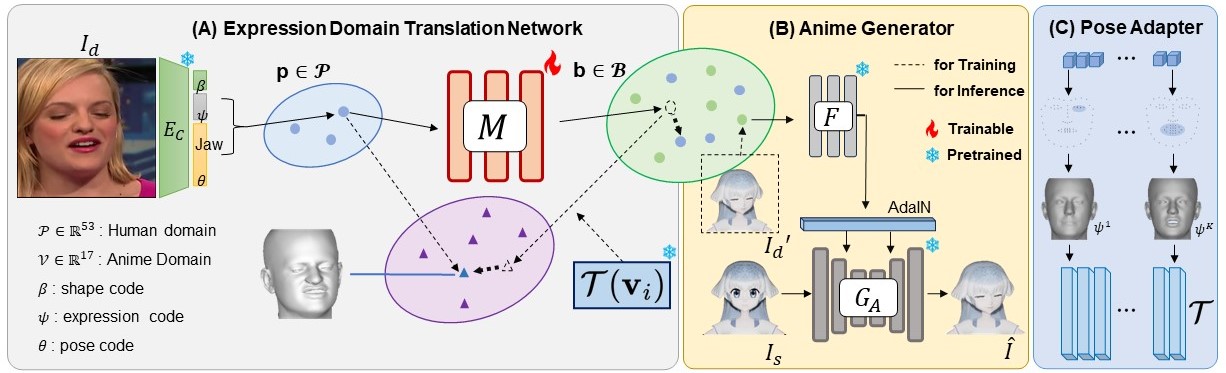
















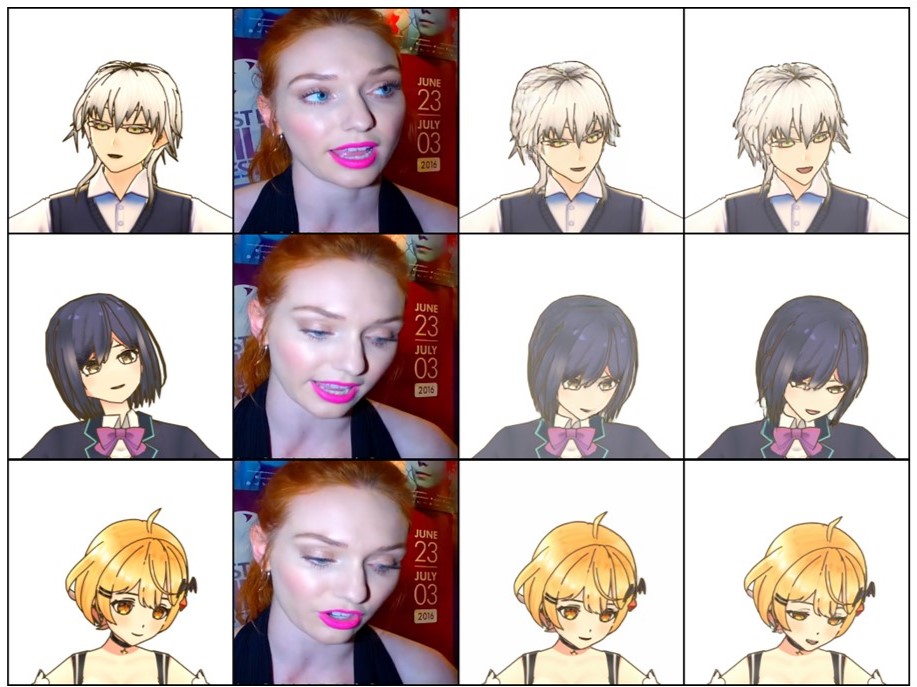







@misc{kang2023expression,
title={Expression Domain Translation Network for Cross-domain Head Reenactment},
author={Taewoong Kang and Jeongsik Oh and Jaeseong Lee and Sunghyun Park and Jaegul Choo},
year={2023},
eprint={2310.10073},
archivePrefix={arXiv},
primaryClass={cs.CV}
}